Making asm.js/WebAssembly compilation more parallel in Firefox
Posted on Fri 22 April 2016 in compilers opensource mozilla • 8 min read
In December 2015, I've worked on reducing startup time of asm.js programs in Firefox by making compilation more parallel. As our JavaScript engine, Spidermonkey, uses the same compilation pipeline for both asm.js and WebAssembly, this also benefitted WebAssembly compilation. Now is a good time to talk about what it meant, how it got achieved and what are the next ideas to make it even faster.
What does it mean to make a program "more parallel"?
Parallelization consists of splitting a sequential program into smaller
independent tasks, then having them run on different CPU. If your program
is using N cores, it can be up to N times faster.
Well, in theory. Let's say you're in a car, driving on a 100 Km long road. You've already driven the first 50 Km in one hour. Let's say your car can have unlimited speed from now on. What is the maximal average speed you can reach, once you get to the end of the road?
People intuitively answer "If it can go as fast as I want, so nearby lightspeed
sounds plausible". But this is not true! In fact, if you could teleport from
your current position to the end of the road, you'd have traveled 100 Km in one
hour, so your maximal theoritical speed is 100 Km per hour. This result is a
consequence of Amdahl's law.
When we get back to our initial problem, this means you can expect a N times
speedup if you're running your program with N cores if, and only if your
program can be entirely run in parallel. This is usually not the case, and
that is why most wording refers to speedups up to N times faster, when it
comes to parallelization.
Now, say your program is already running some portions in parallel. To make it faster, one can identify some parts of the program that are sequential, and make them independent so that you can run them in parallel. With respect to our car metaphor, this means augmenting the portion of the road on which you can run at unlimited speed.
This is exactly what we have done with parallel compilation of asm.js programs under Firefox.
A quick look at the asm.js compilation pipeline
I recommend to read this blog post. It clearly explains the differences between JIT (Just In Time) and AOT (Ahead Of Time) compilation, and elaborates on the different parts of the engines involved in the compilation pipeline.
As a TL;DR, keep in mind that asm.js is a strictly validated, highly optimizable, typed subset of JavaScript. Once validated, it guarantees high performance and stability (no garbage collector involved!). That is ensured by mapping every single JavaScript instruction of this subset to a few CPU instructions, if not only a single instruction. This means an asm.js program needs to get compiled to machine code, that is, translated from JavaScript to the language your CPU directly manipulates (like what GCC would do for a C++ program). If you haven't heard, the results are impressive and you can run video games directly in your browser, without needing to install anything. No plugins. Nothing more than your usual, everyday browser.
Because asm.js programs can be gigantic in size (in number of functions as well as in number of lines of code), the first compilation of the entire program is going to take some time. Afterwards, Firefox uses a caching mechanism that prevents the need for recompilation and almost instaneously loads the code, so subsequent loadings matter less*. The end user will mostly wait for the first compilation, thus this one needs to be fast.
Before the work explained below, the pipeline for compiling a single function (out of an asm.js module) would look like this:
- parse the function, and as we parse, emit intermediate representation (IR) nodes for the compiler infrastructure. SpiderMonkey has several IRs, including the MIR (middle-level IR, mostly loaded with semantic) and the LIR (low-level IR closer to the CPU memory representation: registers, stack, etc.). The one generated here is the MIR. All of this happens on the main thread.
- once the entire IR graph is generated for the function, optimize the MIR graph (i.e. apply a few optimization passes). Then, generate the LIR graph before carrying out register allocation (probably the most costly task of the pipeline). This can be done on supplementary helper threads, as the MIR optimization and LIR generation for a given function doesn't depend on other ones.
- since functions can call between themselves within an asm.js module, they need references to each other. In assembly, a reference is merely an offset to somewhere else in memory. In this initial implementation, code generation is carried out on the main thread, at the cost of speed but for the sake of simplicity.
So far, only the MIR optimization passes, register allocation and LIR generation were done in parallel. Wouldn't it be nice to be able to do more?
* There are conditions for benefitting from the caching mechanism. In particular, the script should be loaded asynchronously and it should be of a consequent size.
Doing more in parallel
Our goal is to make more work in parallel: so can we take out MIR generation from the main thread? And we can take out code generation as well?
The answer happens to be yes to both questions.
For the former, instead of emitting a MIR graph as we parse the function's body, we emit a small, compact, pre-order representation of the function's body. In short, a new IR. As work was starting on WebAssembly (wasm) at this time, and since asm.js semantics and wasm semantics mostly match, the IR could just be the wasm encoding, consisting of the wasm opcodes plus a few specific asm.js ones*. Then, wasm is translated to MIR in another thread.
Now, instead of parsing and generating MIR in a single pass, we would now parse and generate wasm IR in one pass, and generate the MIR out of the wasm IR in another pass. The wasm IR is very compact and much cheaper to generate than a full MIR graph, because generating a MIR graph needs some algorithmic work, including the creation of Phi nodes (join values after any form of branching). As a result, it is expected that compilation time won't suffer. This was a large refactoring: taking every single asm.js instructions, and encoding them in a compact way and later decode these into the equivalent MIR nodes.
For the second part, could we generate code on other threads? One structure in
the code base, the MacroAssembler, is used to generate all the code and it
contains all necessary metadata about offsets. By adding more metadata there to
abstract internal calls **, we can describe the new scheme in terms of a
classic functional map/reduce:
- the wasm IR is sent to a thread, which will return a MacroAssembler. That
is a
mapoperation, transforming an array of wasm IR into an array of MacroAssemblers. - When a thread is done compiling, we merge its MacroAssembler into one big
MacroAssembler. Most of the merge consists in taking all the offset metadata
in the thread MacroAssembler, fixing up all the offsets, and concatenate the
two generated code buffers. This is equivalent to a
reduceoperation, merging each MacroAssembler within the module's one.
At the end of the compilation of the entire module, there is still some light work to be done: offsets of internal calls need to be translated to their actual locations. All this work has been done in this bugzilla bug.
* In fact, at the time when this was being done, we used a different superset of wasm. Since then, work has been done so that our asm.js frontend is really just another wasm emitter.
**** ** referencing functions by their appearance order index in the module, rather than an offset to the actual start of the function. This order is indeed stable, from a function to the other.
Results
Benchmarking has been done on a Linux x64 machine with 8 cores clocked at 4.2 Ghz.
First, compilation times of a few asm.js massive games:
The X scale is the compilation time in seconds, so lower is better. Each value point is the best one of three runs. For the new scheme, the corresponding relative speedup (in percentage) has been added:
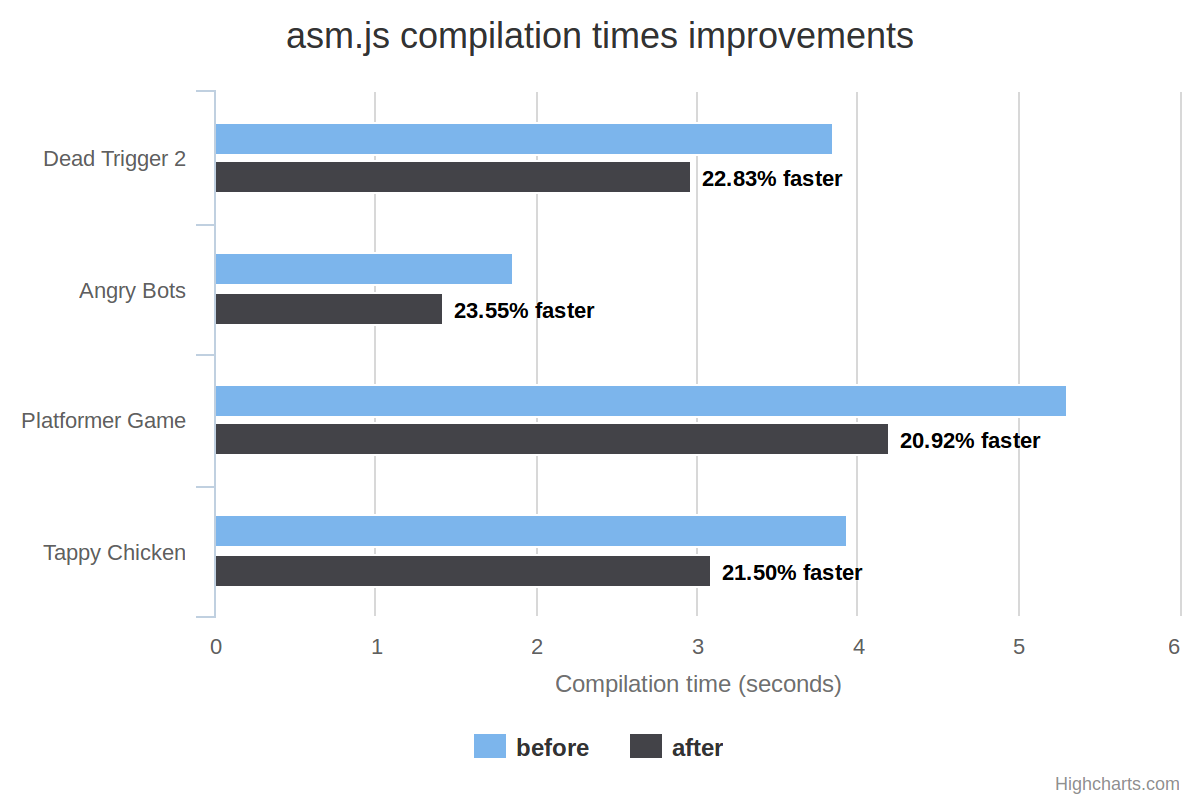
For all games, compilation is much faster with the new parallelization scheme.
Now, let's go a bit deeper. The Linux CLI tool perf has a stat command
that gives you an average of the number of utilized CPUs during the program
execution. This is a great measure of threading efficiency: the more a CPU is
utilized, the more it is not idle, waiting for other results to come, and thus
useful. For a constant task execution time, the more utilized CPUs, the more
likely the program will execute quickly.
The X scale is the number of utilized CPUs, according to the perf stat
command, so higher is better. Again, each value point is the best one of three
runs.
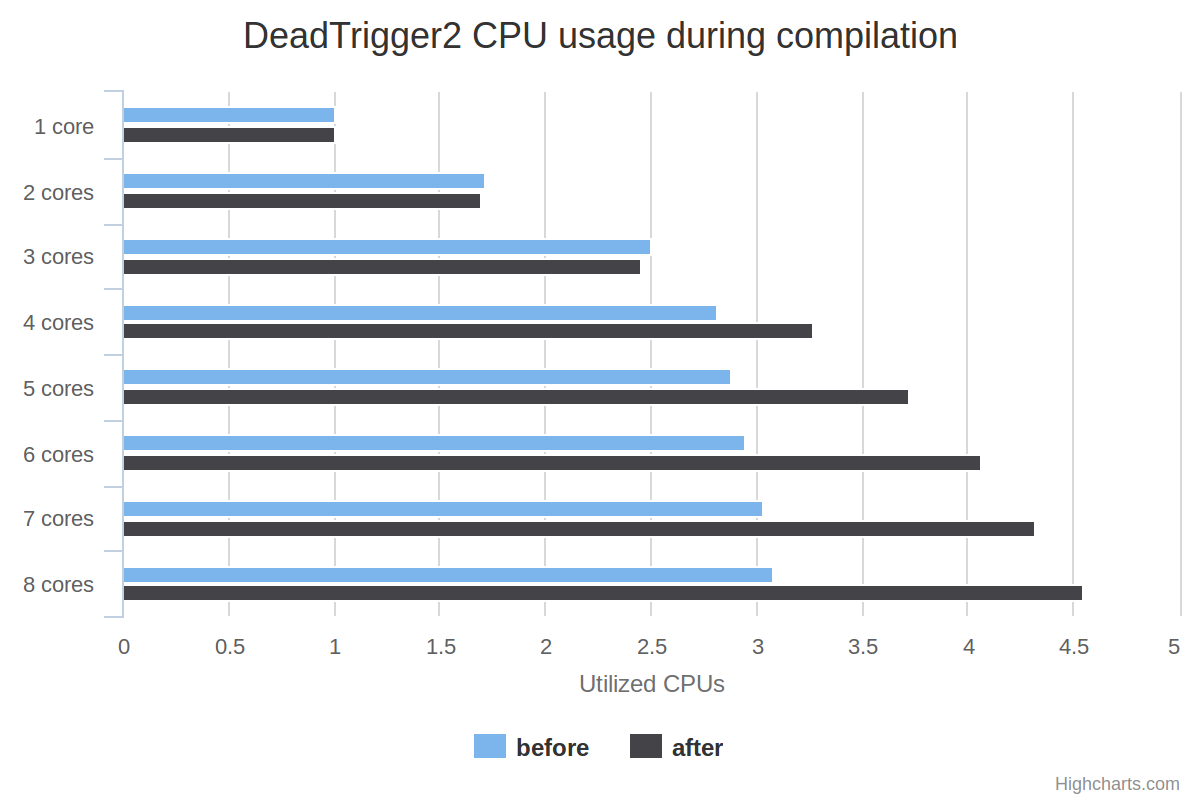
With the older scheme, the number of utilized CPUs quickly rises up from 1 to 4 cores, then more slowly from 5 cores and beyond. Intuitively, this means that with 8 cores, we almost reached the theoritical limit of the portion of the program that can be made parallel (not considering the overhead introduced by parallelization or altering the scheme).
But with the newer scheme, we get much more CPU usage even after 6 cores! Then it slows down a bit, although it is still more significant than the slow rise of the older scheme. So it is likely that with even more threads, we could have even better speedups than the one mentioned beforehand. In fact, we have moved the theoritical limit mentioned above a bit further: we have expanded the portion of the program that can be made parallel. Or to keep on using the initial car/road metaphor, we've shortened the constant speed portion of the road to the benefit of the unlimited speed portion of the road, resulting in a shorter trip overall.
Future steps
Despite these improvements, compilation time can still be a pain, especially on mobile. This is mostly due to the fact that we're running a whole multi-million line codebase through the backend of a compiler to generate optimized code. Following this work, the next bottleneck during the compilation process is parsing, which matters for asm.js in particular, which source is plain text. Decoding WebAssembly is an order of magnitude faster though, and it can be made even faster. Moreover, we have even more load-time optimizations coming down the pipeline!
In the meanwhile, we keep on improving the WebAssembly backend. Keep track of our progress on bug 1188259!